There are two alternatives available - ask- ambiguous and ask- unambiguous. For evaluating the tree (see Section 2.13), the first agent must evaluate the second agent's decision at level 2, and then evaluate the chosen branch of the tree using level 1. In particular, from the first agent's perspective, the chance node at the third move is evaluated at level 1, whereas when the first agent takes the second agent's perspective, it is evaluated at level 3.
ask-unambiguous has a straightforward utility value:
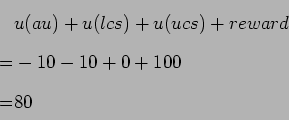 |
(4.6) |
On the other hand, ask-ambiguous is more complicated, because the responding agent's decision changes with the decision surface at ![]() . There are thus two cases:
. There are thus two cases:
if ![]()
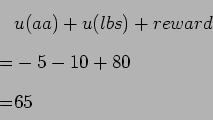 |
(4.7) |
if ![]()
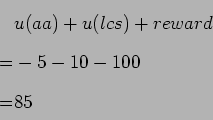 |
(4.8) |
Therefore, when ![]() the non-risky alternative (80) is better than the risky alternative (65). On the other hand, if
the non-risky alternative (80) is better than the risky alternative (65). On the other hand, if ![]() , the risky alternative (85) is better than the non-risky alternative (80) . It might then be expected that the utility curve is a step function. It is not quite, because estimation error comes in to play. Near the decision surface, estimation error causes the responding agent's decision to spill across the surface. For instance, if
, the risky alternative (85) is better than the non-risky alternative (80) . It might then be expected that the utility curve is a step function. It is not quite, because estimation error comes in to play. Near the decision surface, estimation error causes the responding agent's decision to spill across the surface. For instance, if ![]() is estimated at 0.55, it is quite possible that the actual value is 0.45, resulting in a different choice and a different utility value. Using four degrees of estimation error, corresponding with 2, 8, 32, and 128 samples, the sampling version of the planner obtained the curves in figure 4.6
is estimated at 0.55, it is quite possible that the actual value is 0.45, resulting in a different choice and a different utility value. Using four degrees of estimation error, corresponding with 2, 8, 32, and 128 samples, the sampling version of the planner obtained the curves in figure 4.6
The spill is clearly evident in the plot, and has a significant effect on the decision of the agent since the step is so abrupt. For a naive agent, who has only experienced two samples, the decision surface is not at 0.5 but past 0.7. As the number of samples increases, the curve approaches the step function form that was expected of an agent with no estimation error. This demonstration confirms that error estimation, as well as probabilistic reasoning, plays an important role in dialogue decisions. Error estimation also has some effect on the utility curve. Notice that the area under the curve is somewhat greater as ![]() becomes larger. This increased area provides extra impetus for the agent to engage in a dialogue, since what is learned during it improves the agent's performance in later dialogues. The most straightforward way to compute the impetus would be to compute deeper game trees, so that the current dialogue, and the later ones, are accounted for within one game tree. To do so may require algorithms that limit the combinatorial explosion of the game tree, outlined in Section 3.4.9. For example, many instances of the spanner dialogue could be joined to produce a long chain. This approach could also be used to evaluate explicit user model acquisition questions, which can be used when the user is introduced to the system, but whose value is obtained slowly over the course of future dialogues. In general, it makes sense for the planner to plan not just the immediate dialogue, but to construct very deep game trees, so that the value of a belief that is learned about now can be checked by also making evaluations using that belief in the rest of the game tree. Further discussion of this idea is left to the future work section in Chapter 6.
becomes larger. This increased area provides extra impetus for the agent to engage in a dialogue, since what is learned during it improves the agent's performance in later dialogues. The most straightforward way to compute the impetus would be to compute deeper game trees, so that the current dialogue, and the later ones, are accounted for within one game tree. To do so may require algorithms that limit the combinatorial explosion of the game tree, outlined in Section 3.4.9. For example, many instances of the spanner dialogue could be joined to produce a long chain. This approach could also be used to evaluate explicit user model acquisition questions, which can be used when the user is introduced to the system, but whose value is obtained slowly over the course of future dialogues. In general, it makes sense for the planner to plan not just the immediate dialogue, but to construct very deep game trees, so that the value of a belief that is learned about now can be checked by also making evaluations using that belief in the rest of the game tree. Further discussion of this idea is left to the future work section in Chapter 6.
![\includegraphics[width=0.9\textwidth]{figures/spanner_plantree_exp2.eps}](img47.png)
![\includegraphics[width=0.9\textwidth]{figures/e2.eps}](img52.png)